Enjeux techniques et défis méthodologiques de l’ingénierie de terrain au service de la recherche
La captation d’un séminaire polyartéfacté
English
version >
Justine Lascar, Oriane Dujour, « Enjeux techniques et défis
méthodologiques de l’ingénierie de terrain au service de la
recherche », Fabrique de l’interaction parmi les écrans :
formes de présences en recherche et en
formation (édition augmentée), Les Ateliers de [sens
public], Montréal, 2021, isbn:978-2-924925-13-3, http://ateliers.sens-public.org/fabrique-de-l-interaction-parmi-les-ecrans/annexe.html.
version:0, 15/06/2021
Creative
Commons Attribution-ShareAlike 4.0 International (CC BY-SA 4.0)
La production et le traitement des corpus ne soulèvent pas que des questions méthodologiques mais impliquent une réflexion sur l’articulation entre le travail de recueil des données et les exigences de l’analyse. Dans le champ de l’analyse linguistique de l’interaction, cela se traduit notamment par une attention pour les détails linguistiques et multimodaux produits, mobilisés, interprétés par les participant·e·s et rendus disponibles par des techniques adéquates d’enregistrement, de transcription et d’analyse. Autrement dit, l’exigence d’accessibilité continuelle des détails pertinents des interactions gouverne toutes les étapes de la constitution et de l’analyse des corpus : du recueil sur le terrain à la phase de « confection », qui comporte aussi bien le montage audiovisuel, la transcription, l’alignement, l’annotation, jusqu’à la phase d’analyse proprement dite.
Les différentes étapes de cette démarche menée dans le traitement du corpus « Présences numériques »Le corpus « Présences numériques » est disponible sur la plateforme Ortolang.↩︎ sont ici décrites en considérant l’imbrication de nombreuses dimensions : techniques, méthodologiques, théoriques, juridiques.
Dispositif de captation
La première étape du travail d’analyse des interactions est la collecte des données en situation. Loin de constituer une étape préliminaire, secondaire et marginale, que l’on pourrait concevoir indépendamment des objectifs analytiques, le recueil des données fait partie intégrante du processus global de l’analyse.
Recueillir les données n’est pas une étape ponctuelle et purement technique, c’est une entreprise qui fait intervenir la connaissance du terrain et les relations des collecteur·rice·s avec les différent·e·s acteur·rice·s concernés, les dimensions pratiques et techniques de l’enregistrement.
Dans la tradition des méthodes de captation de l’analyse conversationnelle et des sciences de l’éducation, nous avons réalisé des enregistrements des séminaires IMPEC grâce à plusieurs caméras afin de multiplier les points de vue. Cela nous a permis de conserver l’écologie de la situation et d’avoir accès à tous les détails des interactions comme les regards, les gestes, les postures mais également à toute la communication en ligne grâce aux capture d’écran des différents artefacts mobilisés pendant le séminaire (Adobe Connect, robots de téléprésence Kubi et Beam). Ce terrain de recherche a commencé alors que nous venions de nous équiper de nouveaux dispositifs de captation, notamment des caméras Action Cam comme les GoPro et la Sony Action Cam, mais également des caméras 360° Kodak SP360. Celles-ci nous ont non seulement permis de disposer ces équipements dans des endroits jusqu’ici inaccessibles avec des caméras sur trépied classique, mais également d’avoir des plans plus globaux grâce à leur lentille wide lens intégrée. Le terrain de recherche de « Présences numériques » nous a donc permis de tester ces différents équipements et d’avoir une réflexion sur leurs spécificités et leur apports pour l’analyse des interactions.
Les membres du groupe « Présences numériques » nous ont ouvert les portes du séminaire en nous permettant de tester différentes configurations de dispositifs. La salle du Laboratoire d’Innovation Pédagogique et Numérique (LiPen) est un espace conçu pour mobiliser des outils méthodologiques collaboratifs, elle se situe au sein de l’Institut Français d’Éducation (IFÉ) à l’ENS de Lyon. Le recueil de données a du prendre en compte les contraintes liées au lieu et celles liées aux différentes modalités du séminaire.
Le lieu :
- la salle possède une paroi en verre qui a posé des problèmes dans la disposition des caméras pour éviter les contre-jours,
- il y a un mur entier de projection-tableau blanc qui nous a également contraint dans le placement des caméras,
- le mobilier est modulable et il y a des prises au sol. Nous avons du le prendre en compte pour les trajets du robot Beam notamment.

L’organisation du séminaire :
- plusieurs configurations ont été testées, en mode conférence avec le ou les conférencier·e·s au centre face au public en U, en mode groupes de travail regroupés autour de deux tables en L, et une fois en mode conférence où la conférencière pilote le robot Beam et le public se tient face à elle autour d’une table en L. Dans chaque cas, le dispositif de captation a été spécifique.


Captation vidéo
L’enregistrement des corpus est une opération matérielle et technique qui doit être conçue et réalisée en fonction d’objectifs et d’objets d’analyse. Cette opération vise à capturer des données audio et vidéo afin de rendre disponibles, et donc analysables, les détails linguistiques, multimodaux et situationnels (regards, gestes, mouvements, actions, objets, cadre physique) pertinents pour l’interaction enregistrée.
Ces détails pertinents sont à la fois :
- ceux que les participant·e·s exploitent de manière située pour produire et interpréter l’intelligibilité de leurs conduites,
- ceux que les analystes exploitent pour rendre compte de l’organisation de l’interaction, sur la base des orientations montrées par les participant·e·s.
Les enregistrements sont donc régis par la nécessité de prendre en compte
- le déroulement temporel de l’interaction,
- l’écologie de l’interaction, i.e. la manière dont elle se déploie dans l’espace,
- le cadre de participation qui caractérise l’interaction,
- les objets qui sont mobilisés par les interactant·e·s.
La réalisation de ces objectifs a nécessité l’usage d’une variété de matériels d’enregistrement.
Tout d’abord, nous avons utilisé deux caméscopes Sony XR550 sur des trépieds pour avoir deux points de vue sur le séminaire :
- la première caméra était orientée sur l’assistance - Vue 1.

- la deuxième était disposée en fond de salle en direction de ou des conférencier·e·s et pour recueillir les contenus vidéoprojetés sur le mur (Adobe Connect et diaporama de présentation). Dans la configuration « travail de groupe », les deux vues étaient complémentaires - Vue 2.

Une caméra GoPro Hero5 était positionnée sur un tableau blanc en hauteur grâce à un GorillaPod magnétique pour avoir une vue d’ensemble sur la salle et les déplacements du robot Beam - Vue GP.

Ces trois vues sont présentes pour tous les séminaires enregistrés.
Nous avons également testé lors de la première séance une caméra Kodak SP360. Positionnée sur un meuble pour être à hauteur des visages des interactant·e·s, elle gênait les déplacements du robot Beam. De plus, l’analyse des données en 360° est complexe car il s’agit de construire un point de vue a posteriori. Nous avons donc abandonné cette solution pour les séances suivantes.


Suivant les participant·e·s à distance, différent·e·s à chaque séance, nous avons dû prendre en compte les artefacts numériques mobilisés et réfléchir à la façon de récolter leurs traces.
Pour le Beam, nous avons demandé à la pilote d’enregistrer son écran ainsi qu’une vue de son environnement la montrant en train d’interagir devant son écran.
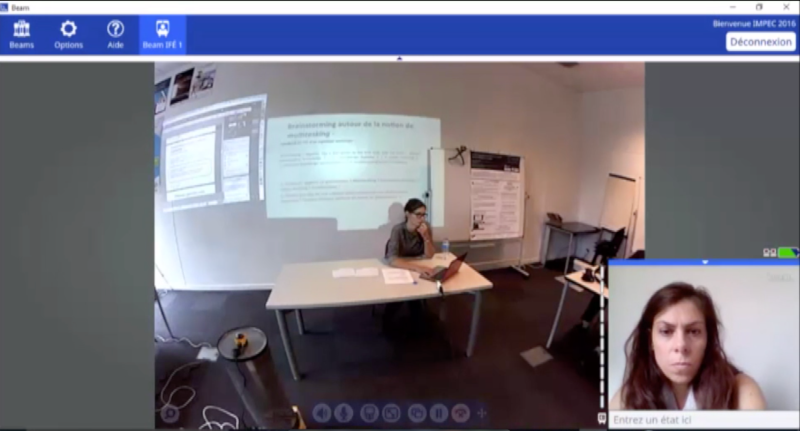

Pour Adobe Connect à distance, nous avons procédé de la même façon avec une des collègues à Aix-en-Provence.
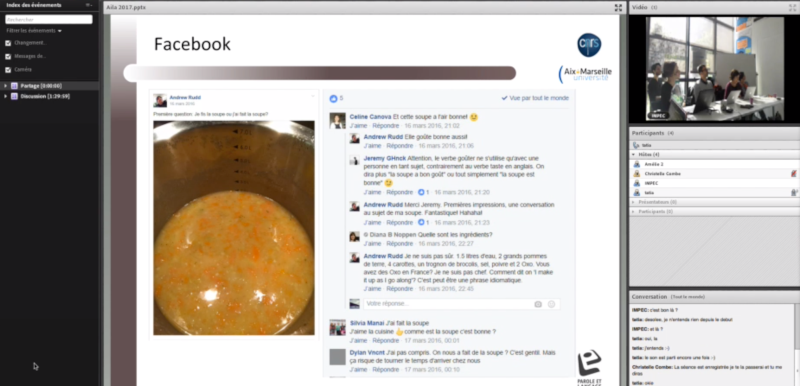

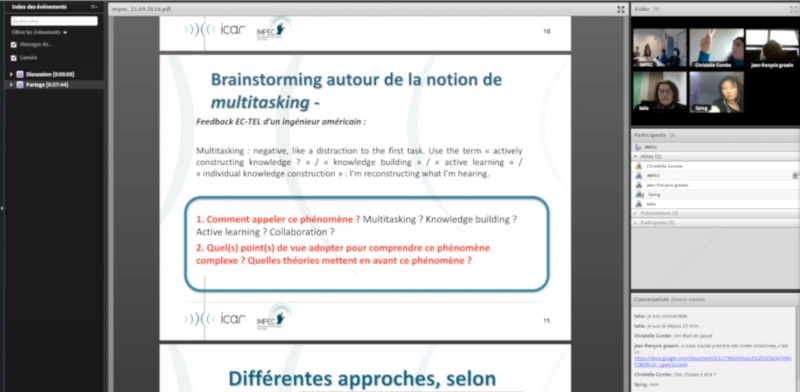
Pour Adobe Connect in situ, à Lyon, nous avons aussi récolté une capture d’écran d’une participante présente dans la salle du LiPeN ainsi que la projection de l’interface sur le mur du LiPeN grâce à la caméra vue 1.
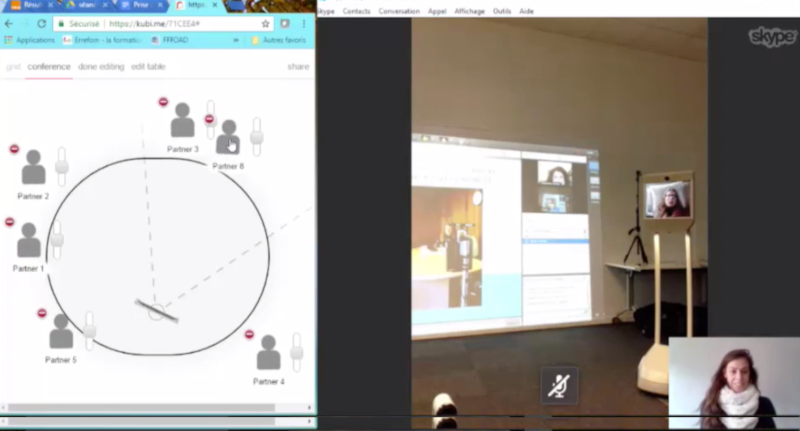
En ce qui concerne le Kubi, il nous était impossible de récupérer le flux directement sur l’iPad, le cumul de la commande à distance et de la capture d’écran dynamique faisant laguer la connexion. Nous avons donc récupéré les mouvements du Kubi et l’image de l’iPad grâce à une caméra Action Cam Sony posée à quelques centimètres de l’artefact grâce à son grand angle intégré. Pour compléter, l’écran de l’ordinateur qui contrôlait le Kubi à distance a également été capté.

Pour chaque séance, nous avons donc entre cinq et huit flux vidéos différents – entre trois et quatre vues in situ et entre deux et quatre vues et captures d’écran dynamiques à distance.
Captation audio
Pour capter le son des séminaires, nous avons utilisé des micros Sennheiser EW 100 HF, sans fil, reliés à un enregistreur zoom H6 multipiste. Un micro était porté par Christine, un par le·la conférencier·e et deux autres étaient disposés dans la salle, sur les tables proches des participant·e·s, isolés par une mousse.
L’enregistreur multipiste permet de monitorer le son hors de la salle et de récupérer les pistes synchronisées.

Pour chaque séance, nous avons donc quatre flux audio distincts.
Montage et export
La phase de montage est tout aussi importante pour rendre disponibles et intelligibles tous les éléments de l’interaction. La Cellule Corpus Complexes (CCC), structure transversale de soutien à la recherche au laboratoire ICAR, met son expertise à profit dans le traitement des données en post-production (synchronisation des différentes sources, anonymisation, montage audio et vidéo…).
Nous travaillons sur le logiciel Final Cut Pro X sur Mac. Après avoir créé une bibliothèque qui regroupe toutes les données du corpus et sert d’archive, nous avons importé tous les flux enregistrés et récupérés. Les résolutions, débits, nombres d’images par seconde peuvent être différents selon les sources. Nous les avons répertoriés et analysés pour prévenir d’éventuels problèmes de traitement. La première étape importante est celle de la synchronisation des différents flux audio et vidéo disponibles pour chaque séminaire (entre huit et douze pistes). Si une partie peut être automatisée en se basant sur les bandes sonores des différents flux, une autre est réalisée manuellement.
Une fois la synchronisation terminée, nous avons décidé d’un timing de début et de fin de séance commun à toutes les pistes audio et vidéo. Chaque vue est ainsi exportée comme un fichier unique mais ayant la même durée que tous les autres. Les fichiers vidéos sont exportés en .mp4 avec une résolution de 960x540, permettant d’avoir des fichiers pas trop lourds mais d’une qualité suffisante pour avoir accès aux détails de l’interaction (les fichiers ayant une durée moyenne d’une heure, et un poids d’environ 1,2 Go chacun). En ce qui concerne les pistes audio elles sont reexportées en .wav, pour ne pas avoir de perte d’information.
Une fois les fichiers exportés, on peut facilement naviguer de l’un à l’autre grâce au timing commun.
On peut ensuite créer des montages multivues grâce au logiciel QuickTime Pro 7 suivant les besoins de l’équipe.
Ainsi, nous discutons des vues à privilégier et de leur agencement. Plusieurs montages multiscopes sont réalisés.
Par exemple, uniquement avec les pistes filmées in situ à Lyon :

Avec ces mêmes pistes et la capture d’écran d’Adobe Connect :

Ou encore uniquement avec les artefacts numériques mobilisés :
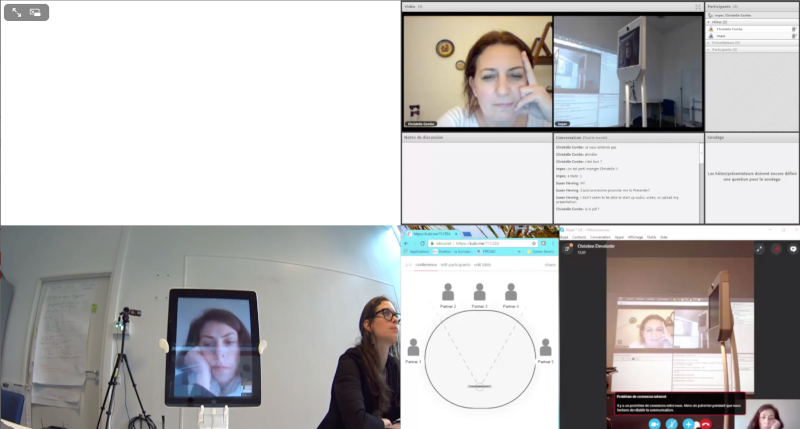
En plus des séances de séminaires, le corpus « Présences numériques » contient 17 entretiens vidéos et audio des différents membres de l’équipe. Ils ont été réalisés après les séminaires en même temps qu’un questionnaire. Les entretiens ont également été transcrits.
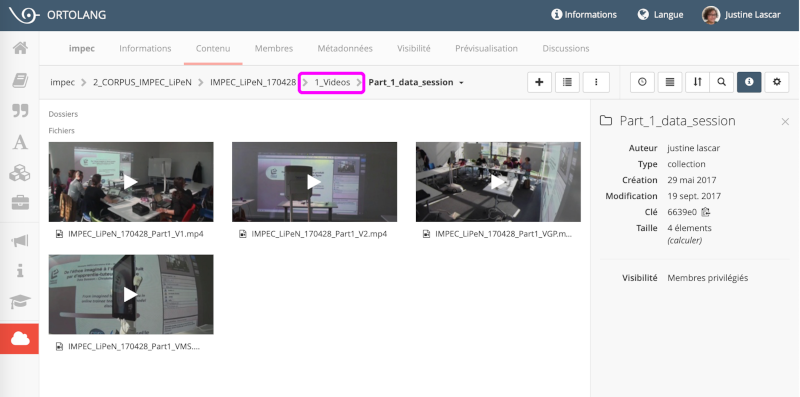
Toutes les pistes audio et vidéo des séminaires, les montages multiscopes ainsi que les entretiens sont mis à disposition de toute l’équipe via la plateforme Ortolang, EquipEx de la TGIR Humanum. Le corpus est structuré et archivé pour être accessible aux membres du groupe de façon sécurisée.
Choix d’édition vidéo effectués en vue d’une édition augmentée
Synopsis, travail collaboratif et méthode
Le choix d’éditer le livre sous format numérique en ligne permet une plus grande liberté pour illustrer les concepts des auteur·rice·s, notamment grâce à la possibilité d’intégrer des vidéos dans le texte. La création des capsules a pour but d’ajouter une couche d’analyse grâce à des procédés de montage, par-dessus les données brutes issues de la captation des séminaires.
Pour faciliter, la compréhension et ne pas interrompre la lecture de l’article, nous avons choisi de réaliser des capsules très courtes (moins de 3 minutes) sur le modèle une capsule = un concept.
La création des capsules a été réalisée en étroite collaboration avec les auteur·rice·s du livre afin de préserver au mieux leur intention. Derrière chaque illustration, technique et analyse sont entremêlées. Les auteur·rice·s nous ont fourni la liste des vidéos étudiées, leurs emplacements dans les articles ainsi que les extraits et vues nécessaires à leur réalisation. Ils·elles ont ensuite réalisé pour chaque capsule vidéo un synopsis écrit regroupant les différents matériaux audiovisuels mais aussi les ajouts (transcription, sous-titrage, focalisation, commentaires…).
Suivant cette trame, nous avons créé un premier montage avec les différents plans et timings demandés et veillé à la synchronisation entre les différentes vues afin d’éviter des décalages temporels.
Nous avons ensuite repris cette épreuve de montage en présence d’un·e représentant·e du chapitre concerné ou en visioconférence lorsque la situation l’exigeaitLe travail d’éditorialisation numérique de l’ouvrage commencé en 2019 s’est poursuivi en 2020, lors du confinement mis en place en raison de la pandémie de la COVID-19. Une partie des capsules a donc été réalisée à distance.↩︎. Le processus résulte du dialogue entre le ou la chercheur·e et les membres de la Cellule Corpus Complexes, autour des propositions techniques. On utilise en effet les outils de montage audiovisuel pour interpréter le discours du·de la chercheur·e.
Le statut de la vidéo change : on passe de la donnée brute à un produit issu de l’analyse de cette donnée. Le but est de montrer le point de vue du ou de la chercheur·e, c’est-à-dire de montrer l’analyse par le montage.

Les capsules vidéo sont traitées comme des éléments indissociables de l’analyse rédigée dans les articles, plutôt que comme des objets indépendants. De ce fait, nous avons fait le choix de ne pas contextualiser l’extrait en détaillant le propos dans la vidéo, puisque ces éléments sont disponibles dans l’article associé. Cela permet d’éviter la surcharge d’informations visuelles et de raccourcir considérablement la durée de la capsule, pour ne pas être redondant avec l’analyse écrite.
Focaliser l’attention par le montage
Pour illustrer les concepts des auteur·rice·s, nous avons utilisé des procédés de montage afin de mettre en avant certains éléments précis du corpus de données. Par exemple, pour focaliser l’attention du·de la lecteur·rice sur une partie d’une scène nous avons utilisé ces différentes techniques :
- le zoom progressif – il permet d’agrandir un élément, plus ou moins vite selon le rythme de l’extrait, soit pour recouvrir complètement le plan en dessous soit en laissant une superposition visible afin de montrer plusieurs choses à la fois. Nous nous en sommes particulièrement servi pour faire apparaître des plans dans l’artefact d’où ils sont tirés (par exemple zoom sur la vue de l’écran du Kubi qui sort de ce dernier). D’un point de vue analytique, le zoom permet de traduire la focalisation.
- le recadrage – le plan est recoupé, généralement après avoir été agrandi, afin de retirer les éléments superflus à l’image. L’action de recadrage peut être réalisée soit en faisant apparaître le cadrage initial et le changement de cadre ou en ne faisant apparaître que le plan recoupé.
- le flou – en cas de superposition de plans, par exemple suite à un zoom progressif, l’application d’un flou sur le plan inférieur permet de rendre ce dernier moins visible et de donner moins d’informations visuelles au·à la lecteur·rice. Nous l’avons utilisé notamment lorsque l’accent devait être mis sur la fenêtre du chat d’Adobe Connect.
- les cercles – plus simplement, nous avons souvent utilisé des cercles turquoise pour attirer l’attention du spectateur sur un élément précis ou pour relier un carton descriptif à l’élément qu’il concerne.
De même, selon le contexte, nous avons sélectionné les pistes audio à utiliser et manipuler afin de focaliser sur les échanges, ou à l’inverse, de réduire les informations sonores.
Ajuster le rythme des capsules
Il était important de rythmer les capsules pour qu’elles restent courtes et que le ou la lecteur·rice ne soit pas coupé·e trop longtemps de la lecture.
De manière générale, nous avons principalement utilisé des coupes pour changer de plans mais dans certains cas nous avons utilisé le zoom pour indiquer de quelle interface provient le nouveau plan. Lorsqu’il était important d’avoir plusieurs vues simultanément (par exemple pour montrer une même action sous deux angles différents), nous avons utilisé le split screen, c’est-à-dire que nous avons divisé l’écran en deux parties ou plus, chacune remplie par un plan différent.
Pour les cas où l’analyse portait sur un long extrait voire sur une séance complète, nous avons usé de deux procédés :
- l’accélération – qui consiste en une multiplication par huit ou plus de la vitesse de la vidéo,
- le fondu au noir entre deux plans – le premier plan s’assombrit jusqu’à ce que l’écran soit complètement noir puis le second plan apparaît progressivement afin d’indiquer un saut temporel.
Transmettre une analyse claire
La clarté des situations passe notamment par une contextualisation visuelle des plans superposés. Il y a pour cela la technique du zoom depuis l’artefact sus-mentionnée mais également des filtres appliqués sur les plans. Par exemple, afin de signaler au spectateur les séquences dont la vitesse a été accélérée, nous avons appliqué un effet visuel (Trame dans Final Cut Pro), qui strie l’image de fines bandes vertes, et ajouté une double flèche animée, similaire au symbole d’avance rapide sur les magnétoscopes.
Autre exemple, pour les plans issus d’une des caméras d’enregistrement nous avons utilisé le filtre cam recorder qui applique un cadre et un symbole d’enregistrement en cours.
Pour expliciter certains passages de la vidéo où transmettre un point d’analyse précis des chercheur·e·s, nous avons également employé des cartons de texte :
- Texte en police Courrier blanc sur bandeau gris foncé – utilisé pour les transcriptions des paroles orales lorsque ces dernières sont importantes pour l’analyse.
- Texte en police Comfortaa noir sur bandeau turquoise – utilisé pour décrire ou contextualiser une action, et pour proposer une analyse.
- Texte en police Comfortaa noir dans bulle turquoise – utilisé pour les messages postés dans le chat. La forme et l’animation de la bulle rappellent celles des messageries instantanées.
Il est souvent délicat de trouver un bon compromis entre clarté des explications textuelles et brièveté de ces dernières qui doivent être aisément lisibles sans trop perturber l’attention lors du visionnage de la capsule. Le choix des phrases intégrées dans le montage est proposé par les auteur·rice·s et des reformulations sont choisies ensemble.
Export et archivage
Pour diffuser les vidéos, la problématique principale était de trouver un lieu de stockage sécurisé, pérenne et permettant la diffusion sur le site de l’éditeur. Nous avons choisi de les héberger sur la plateforme ATV (Archivage et Transcodage Vidéo) créée et gérée au sein de l’ENS. Nous y avons donc archivé les capsules en format .mp4 après les avoir indexées. ATV permet également de déposer des vidéos enrichies, par exemple avec un fichier de sous-titrage.
La collaboration avec les différent·e·s auteur·rice·s de cet ouvrage, issu·e·s de champs disciplinaires variés, a été une expérience véritablement enrichissante. Les membres de la Cellule Corpus Complexes ont été intégré·e·s à l’équipe de recherche, pendant toutes les phases du projet, de la captation des données jusqu’à l’édition de cet ouvrage. Nous nous sommes nourri·e·s mutuellement de nos réflexions et expériences. Cette collaboration de cinq années nous a permis d’explorer, de tester, d’éprouver nos méthodologies de travail, de les enrichir des différents regards disciplinaires, et ce, toujours avec une bienveillance mutuelle.